|
8月21日,DeepSeek在其官宣发布DeepSeek-V3.1的文章中提到,DeepSeek-V3.1使用了UE8M0 FP8 Scale的参数精度。另外,V3.1对分词器及chat template进行了较大调整,与DeepSeek-V3存在明显差异。DeepSeek官微在置顶留言里表示,UE8M0 FP8是针对即将发布的下一代国产芯片设计。  相关报道DeepSeek发布新模型V3.1 价格涨了但Agent能力提升了 8月21日,业界千呼万唤的R2模型没来,但DeepSeek官方正式发布了新模型V3.1。从命名来看这或许不是一次大的版本更新,更像是前一代DeepSeek-V3模型的小版本迭代。 在X上,DeepSeek将V3.1称为“我们迈向智能体时代的第一步”(our first step toward the agent era)。本次升级主要有三大亮点,其中包括更强的 Agent能力、混合思考模式和更高的思考效率。 官方表示,通过后训练优化,新模型在工具使用与智能体任务中的表现有较大提升。在编程智能体、搜索智能体测评中, V3.1 相比之前的 DeepSeek 系列模型都有明显提高。  DeepSeek-V3.1 是混合推理架构,一个模型同时支持思考模式和非思考模式。目前用户可在官方 App与网页端体验新模型,通过“深度思考”按钮,实现思考模式与非思考模式的自由切换。DeepSeek API 也已同步升级,deepseek-chat对应非思考模式,deepseek-reasoner对应思考模式,且上下文均已扩展为 128K。 “混合推理非常棒。拥有一个能够在深度思考和快速响应之间切换的模型,感觉就像是实用人工智能的未来。”X上有网友表示,“在深度推理和快速反应之间切换真是天才之举。”根据查询调整深度,可以避免在简单任务上过度耗时,同时在需要时进行全面分析。 与之前的版本相比,V3.1也有更高的思考效率。官方表示,DeepSeek-V3.1-Think 在保持与 DeepSeek-R1-0528 相当的答案质量的同时,响应速度更快。 官方测试结果显示,经过思维链压缩训练后,V3.1-Think 在输出 token 数减少 20%-50% 的情况下,各项任务的平均表现与 R1-0528 持平。  同时,V3.1 在非思考模式下的输出长度也得到了有效控制,相比于 DeepSeek-V3-0324 ,能够在输出长度明显减少的情况下保持相同的模型性能。 同步地,DeepSeek进行了价格调整,模型的API接口调用价格有所上涨。自 9 月 6 日凌晨起,取消夜间时段优惠,输入价格上,缓存命中时为0.5元/百万tokens,缓存未命中的价格则为4元/百万tokens(此前V3为2元/百万tokens);输出价格为12元/百万tokens(此前V3为8元/百万tokens)。  官方提到,V3.1的基础模型在V3的基础上重新做了外扩训练,一共增加训练了840B tokens。基础模型与后训练模型均已在Huggingface与魔搭开源。 值得一提的是,DeepSeek此次还宣布增加了对海外模型Anthropic API格式的支持,官方提到这是“为了满足大家对 Anthoripic API 生态的使用需求”,用户可以将 DeepSeek-V3.1 的能力接入Claude Code框架。
(文章来源:界面新闻) |
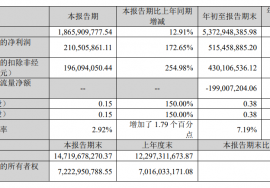
昨天 20:31
昨天 20:30

昨天 20:29
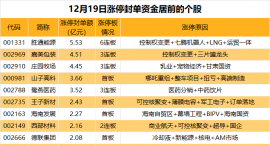
昨天 20:29
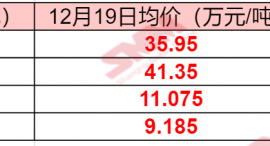
昨天 20:28

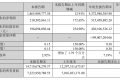
有投资者在投资者互动平台提问:请问公司是否有产品应用于无人机,低空飞行装备上?金

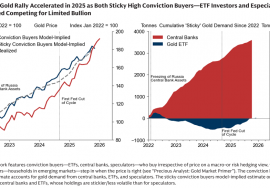
华尔街大行高盛周四(12月18日)发布了一份2026年大宗商品报告,其中指出,在基本假设
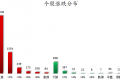
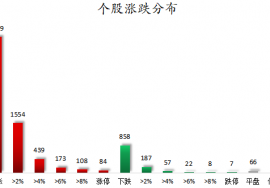
12月19日,上证指数早盘探底回升,午后有所回落;深证成指早盘震荡上扬,临近午盘有所

俄罗斯总统普京今日在莫斯科举行2025年度记者会。普京会对即将过去的一年进行总结,以

热门股胜通能源收获6连板。截至今日(12月19日)收盘,上证指数报收3890.45点,上涨0.
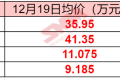
SMM 12月19日讯:本周钴系产品价格继续上涨,对于钴市场而言,原料端的供应紧缺已经成
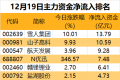
汽车、机械设备行业主力资金净流入均超20亿元。A股三大指数今日(12月19日)集体上涨

文江西日报全媒体记者张锋、毛江凡、胡武龙 ▲敦煌莫高窟第328窟(等比例复制)本文

SMM 12月19日讯:今日早间,汽车零部件板块盘中快速拉涨,指数盘中一度涨逾2%。个股方

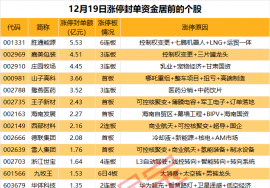
本周166股主力资金净流入1亿元以上。多只高位股尾盘跳水12月19日,A股市场震荡走强。