|
每经记者 文巧 每经编辑 兰素英 
图片来源:发布会视频截图 去年3月,GPT-4震撼发布,距今已逾一年。尽管科技巨头如谷歌、Meta,以及硅谷新贵如Mistral AI、Anthropic在那之后都争相发布了竞品大模型,但似乎至今还未有第二款大模型达到与GPT-4一般横扫科技圈的力量——直到GPT-4o的诞生。 当地时间5月13日,OpenAI在万众期待中推出了名为GPT-4o的新一代旗舰AI模型。当日,OpenAI首席执行官阿尔特曼发推文表示,新的GPT-4o是OpenAI“有史以来最好的模型”。 据悉,GPT-4o支持文字、图像、语音和视频输入和输出,OpenAI承诺未来将免费让普通用户使用,同时将开放API给GPT开发者,价格直接便宜50%。目前,该模型仅开放了文本和图像功能。 本周,《每日经济新闻》记者从图像和文本两大层面深度体验了GPT-4o的效果,着重识图能力的测试。综合来看,GPT-4o在反应速度上有极大的提升,识图方面冠绝群雄,不仅能够准确识别图片,还能以类人的思维理解图像内容。而在长文本总结方面,与当前模型的差距并不突出。 GPT-4o到底是如何“炼”成的?当地时间5月15日,OpenAI联合创始人之一John Schulman在接受科技播客主持人Dwarkesh Patel采访时透露,后训练是提高模型性能的关键因素。 GPT-4o的识图能力有多牛?四大维度深度体验基于图片类型,记者将识图功能的测评分为4大维度,分别为普通图像、特定专业领域的图像、数据图像和手写图像。 一、普通图像识别 (1)内容较为单一的图像 记者首先选取了一张波士顿动力机器人跨越障碍物的图像,内容较为简单,图上无文字,随后要求大模型仔细识图并描述内容。GPT-4o非常出色地完成了任务,细节描述无可匹敌,准确无误地识别了机器人的运动状态、地面障碍等丰富细节。 
图片来源:GPT-4o |


1 小时前

1 小时前

1 小时前
1 小时前

1 小时前


漫画 王建明深圳商报记者 陈燕青量化交易新规实施至今已满两周,A股整体走势震荡向上

(原标题:“国家队”,大消息!) 今年4月,A股市场大幅波动,国家队出手抄底ETF力挽

国家统计局7月15日发布最新数据显示,初步核算,2025年上半年国内生产总值(GDP)6605

日本国会第27届参议院选举初步计票结果显示,由自民党和公明党组成的执政联盟未获参议

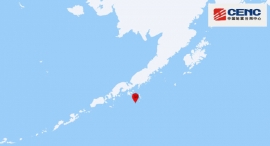
中国地震台网正式测定:07月21日06时28分在美国阿拉斯加州以南海域(北纬54.75度,西

当地时间21日凌晨,总台记者获悉,应欧洲国家要求,伊朗同意与伊核协议中的英、法、德

7月9日在国家铁道试验中心展区拍摄的CR450BF动车组。新华社记者 才扬摄 7月9日,第十

新华社重庆7月20日电(记者谷训)暑假来临,重庆医科大学附属儿童医院一些科室迎来就

总台记者当地时间21日获悉,截至目前的计票结果显示,在本次日本国会参议院选举中

一边是外贸“新三样”中的佼佼者,光鲜亮丽;一边是正经历行业阵痛期的当局者,负












